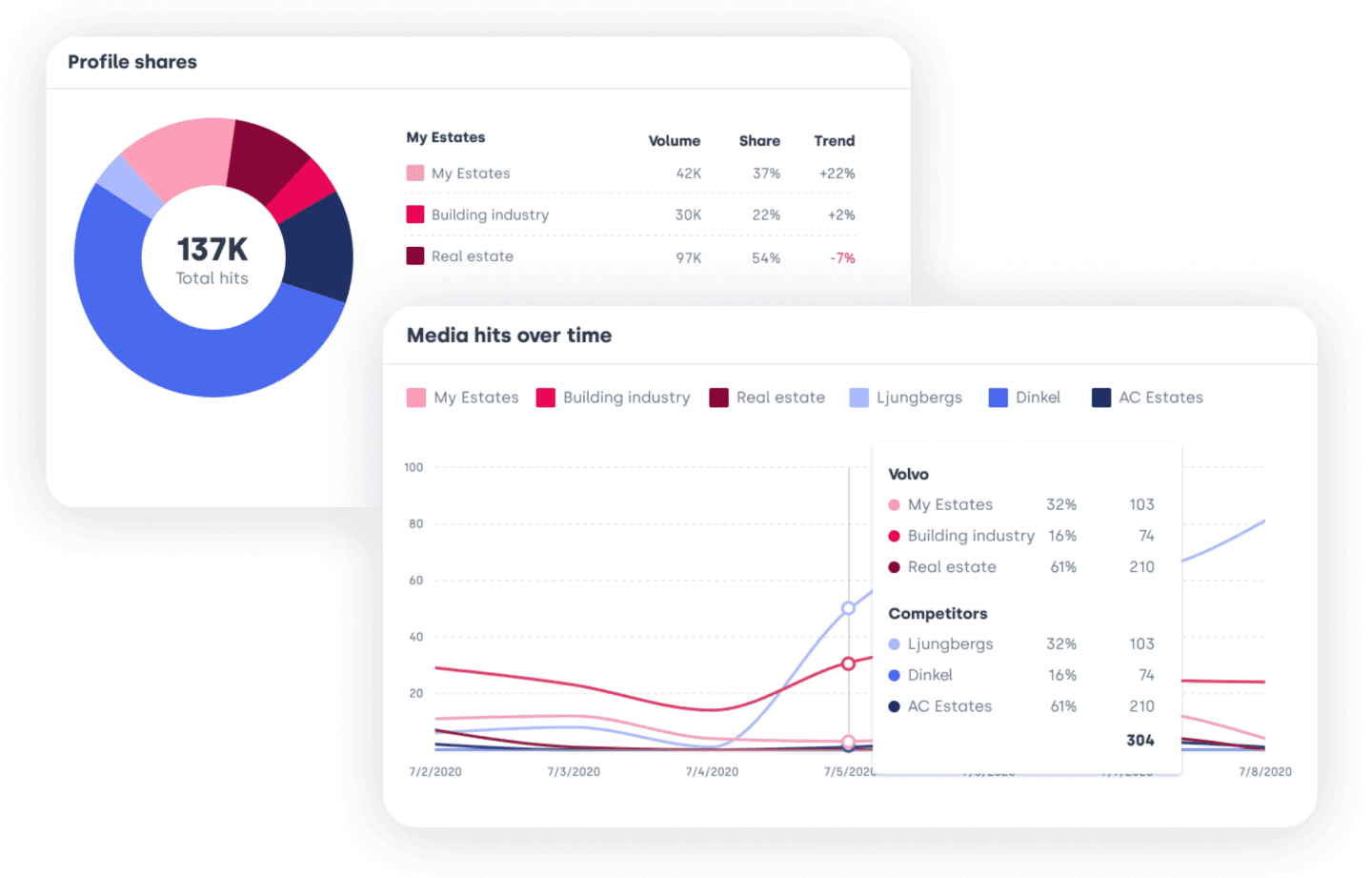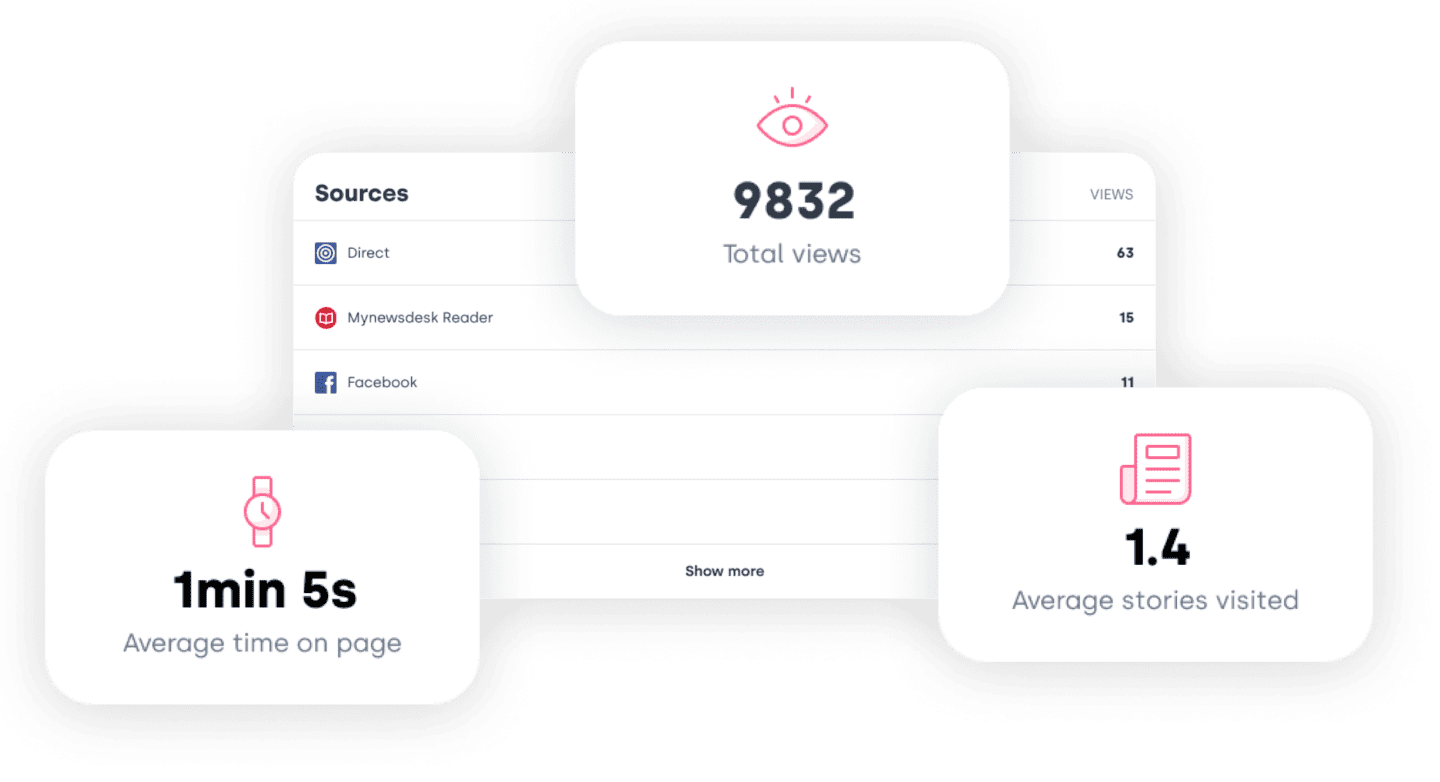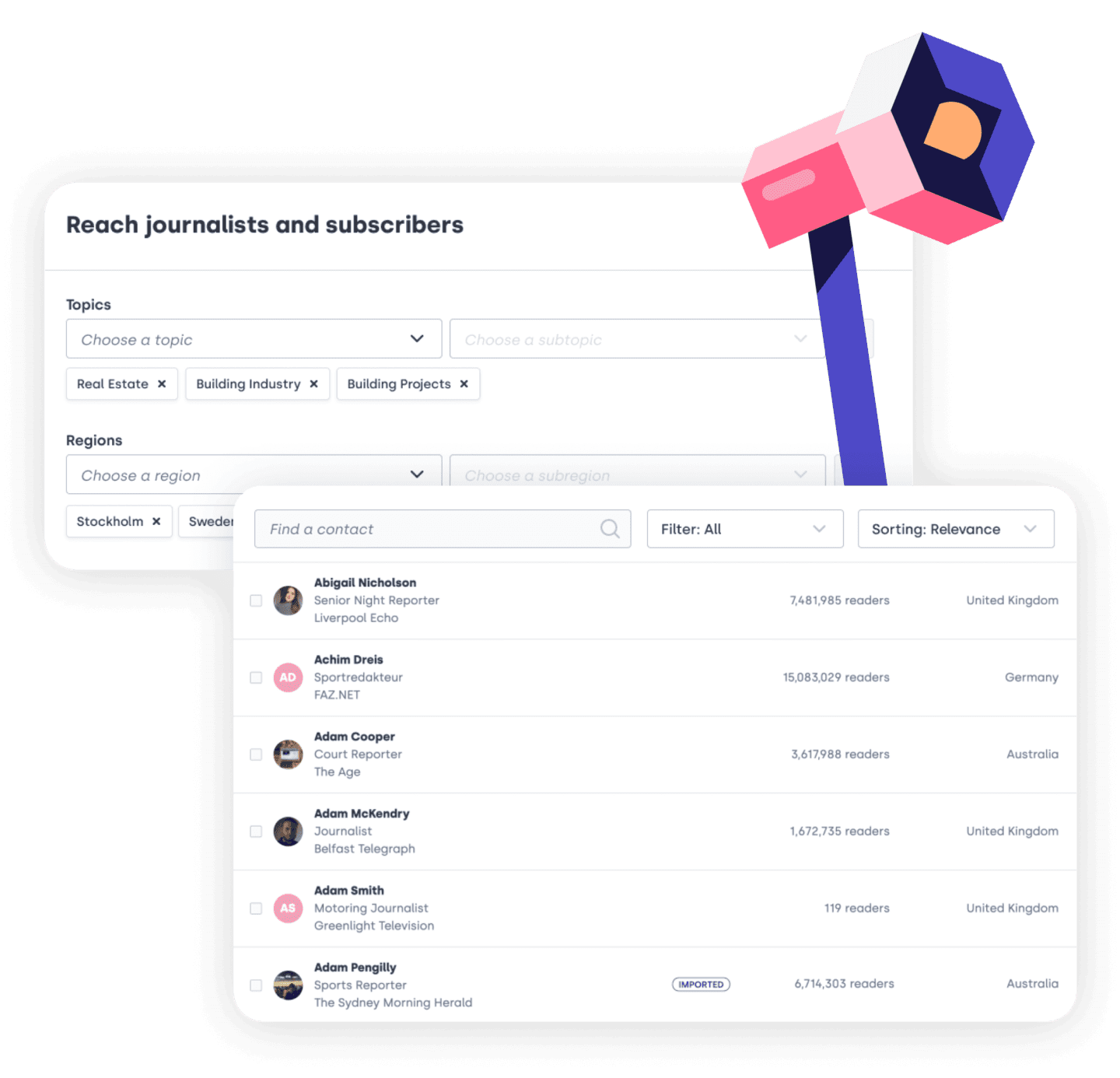
Get your story published
Create and publish your press releases and news in seconds using AI and the Mynewsdesk platform.
Access a database containing more than a million journalists and identify those who are most relevant to your topics.
Share your content on social media or create email send-outs – directly from the platform.